
3 R Basics
Welcome!
This page reviews the essentials of R. It is not intended to be a comprehensive tutorial, but it provides the basics and can be useful for refreshing your memory. The section on Resources for learning links to more comprehensive tutorials.
Parts of this page have been adapted with permission from the R4Epis project.
See the page on Transition to R for tips on switching to R from STATA, SAS, or Excel.
3.1 Why use R?
As stated on the R project website, R is a programming language and environment for statistical computing and graphics. It is highly versatile, extendable, and community-driven.
Cost
R is free to use! There is a strong ethic in the community of free and open-source material.
Reproducibility
Conducting your data management and analysis through a programming language (compared to Excel or another primarily point-click/manual tool) enhances reproducibility, makes error-detection easier, and eases your workload.
Community
The R community of users is enormous and collaborative. New packages and tools to address real-life problems are developed daily, and vetted by the community of users. As one example, R-Ladies is a worldwide organization whose mission is to promote gender diversity in the R community, and is one of the largest organizations of R users. It likely has a chapter near you!
3.2 Key terms
RStudio - RStudio is a Graphical User Interface (GUI) for easier use of R. Read more in the RStudio section.
Objects - Everything you store in R - datasets, variables, a list of village names, a total population number, even outputs such as graphs - are objects which are assigned a name and can be referenced in later commands. Read more in the Objects section.
Functions - A function is a code operation that accept inputs and returns a transformed output. Read more in the Functions section.
Packages - An R package is a shareable bundle of functions. Read more in the Packages section.
Scripts - A script is the document file that hold your commands. Read more in the Scripts section
3.3 Resources for learning
Resources within RStudio
Help documentation
Search the RStudio “Help” tab for documentation on R packages and specific functions. This is within the pane that also contains Files, Plots, and Packages (typically in the lower-right pane). As a shortcut, you can also type the name of a package or function into the R console after a question-mark to open the relevant Help page. Do not include parentheses.
For example: ?filter or ?diagrammeR.
Interactive tutorials
There are several ways to learn R interactively within RStudio.
RStudio itself offers a Tutorial pane that is powered by the learnr R package. Simply install this package and open a tutorial via the new “Tutorial” tab in the upper-right RStudio pane (which also contains Environment and History tabs).
The R package swirl offers interactive courses in the R Console. Install and load this package, then run the command swirl() (empty parentheses) in the R console. You will see prompts appear in the Console. Respond by typing in the Console. It will guide you through a course of your choice.
Cheatsheets
There are many PDF “cheatsheets” available on the RStudio website, for example:
- Factors with forcats package
- Dates and times with lubridate package
- Strings with stringr package
- iterative opertaions with purrr package
- Data import
- Data transformation cheatsheet with dplyr package
- R Markdown (to create documents like PDF, Word, Powerpoint…)
- Shiny (to build interactive web apps)
- Data visualization with ggplot2 package
- Cartography (GIS)
- leaflet package (interactive maps)
- Python with R (reticulate package)
This is an online R resource specifically for Excel users
R has a vibrant twitter community where you can learn tips, shortcuts, and news - follow these accounts:
- Follow us! @epiRhandbook
- R Function A Day @rfuntionaday is an incredible resource
- R for Data Science @rstats4ds
- RStudio @RStudio
- RStudio Tips @rstudiotips
- R-Bloggers @Rbloggers
- R-ladies @RLadiesGlobal
- Hadley Wickham @hadleywickham
Also:
#epitwitter and #rstats
Free online resources
A definitive text is the R for Data Science book by Garrett Grolemund and Hadley Wickham
The R4Epis project website aims to “develop standardised data cleaning, analysis and reporting tools to cover common types of outbreaks and population-based surveys that would be conducted in an MSF emergency response setting.” You can find R basics training materials, templates for RMarkdown reports on outbreaks and surveys, and tutorials to help you set them up.
Languages other than English
3.4 Installation
R and RStudio
How to install R
Visit this website https://www.r-project.org/ and download the latest version of R suitable for your computer.
How to install RStudio
Visit this website https://rstudio.com/products/rstudio/download/ and download the latest free Desktop version of RStudio suitable for your computer.
Permissions
Note that you should install R and RStudio to a drive where you have read and write permissions. Otherwise, your ability to install R packages (a frequent occurrence) will be impacted. If you encounter problems, try opening RStudio by right-clicking the icon and selecting “Run as administrator”. Other tips can be found in the page R on network drives.
How to update R and RStudio
Your version of R is printed to the R Console at start-up. You can also run sessionInfo().
To update R, go to the website mentioned above and re-install R. Alternatively, you can use the installr package (on Windows) by running installr::updateR(). This will open dialog boxes to help you download the latest R version and update your packages to the new R version. More details can be found in the installr documentation.
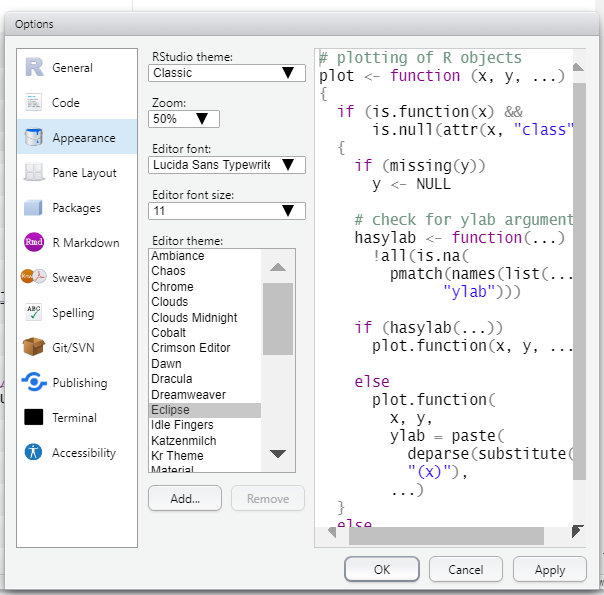
Be aware that the old R version will still exist in your computer. You can temporarily run an older version (older “installation”) of R by clicking “Tools” -> “Global Options” in RStudio and choosing an R version. This can be useful if you want to use a package that has not been updated to work on the newest version of R.
To update RStudio, you can go to the website above and re-download RStudio. Another option is to click “Help” -> “Check for Updates” within RStudio, but this may not show the very latest updates.
To see which versions of R, RStudio, or packages were used when this Handbook as made, see the page on Editorial and technical notes.
Other software you may need to install
- TinyTeX (for compiling an RMarkdown document to PDF)
- Pandoc (for compiling RMarkdown documents)
- RTools (for building packages for R)
- phantomjs (for saving still images of animated networks, such as transmission chains)
TinyTex
TinyTex is a custom LaTeX distribution, useful when trying to produce PDFs from R.
See https://yihui.org/tinytex/ for more informaton.
To install TinyTex from R:
install.packages('tinytex')
tinytex::install_tinytex()
# to uninstall TinyTeX, run tinytex::uninstall_tinytex()Pandoc
Pandoc is a document converter, a separate software from R. It comes bundled with RStudio and should not need to be downloaded. It helps the process of converting Rmarkdown documents to formats like .pdf and adding complex functionality.
RTools
RTools is a collection of software for building packages for R
Install from this website: https://cran.r-project.org/bin/windows/Rtools/
phantomjs
This is often used to take “screenshots” of webpages. For example when you make a transmission chain with epicontacts package, an HTML file is produced that is interactive and dynamic. If you want a static image, it can be useful to use the webshot package to automate this process. This will require the external program “phantomjs”. You can install phantomjs via the webshot package with the command webshot::install_phantomjs().
3.5 RStudio
RStudio orientation
First, open RStudio. As their icons can look very similar, be sure you are opening RStudio and not R.
For RStudio to work you must also have R installed on the computer (see above for installation instructions).
RStudio is an interface (GUI) for easier use of R. You can think of R as being the engine of a vehicle, doing the crucial work, and RStudio as the body of the vehicle (with seats, accessories, etc.) that helps you actually use the engine to move forward! You can see the complete RStudio user-interface cheatsheet (PDF) here
By default RStudio displays four rectangle panes.
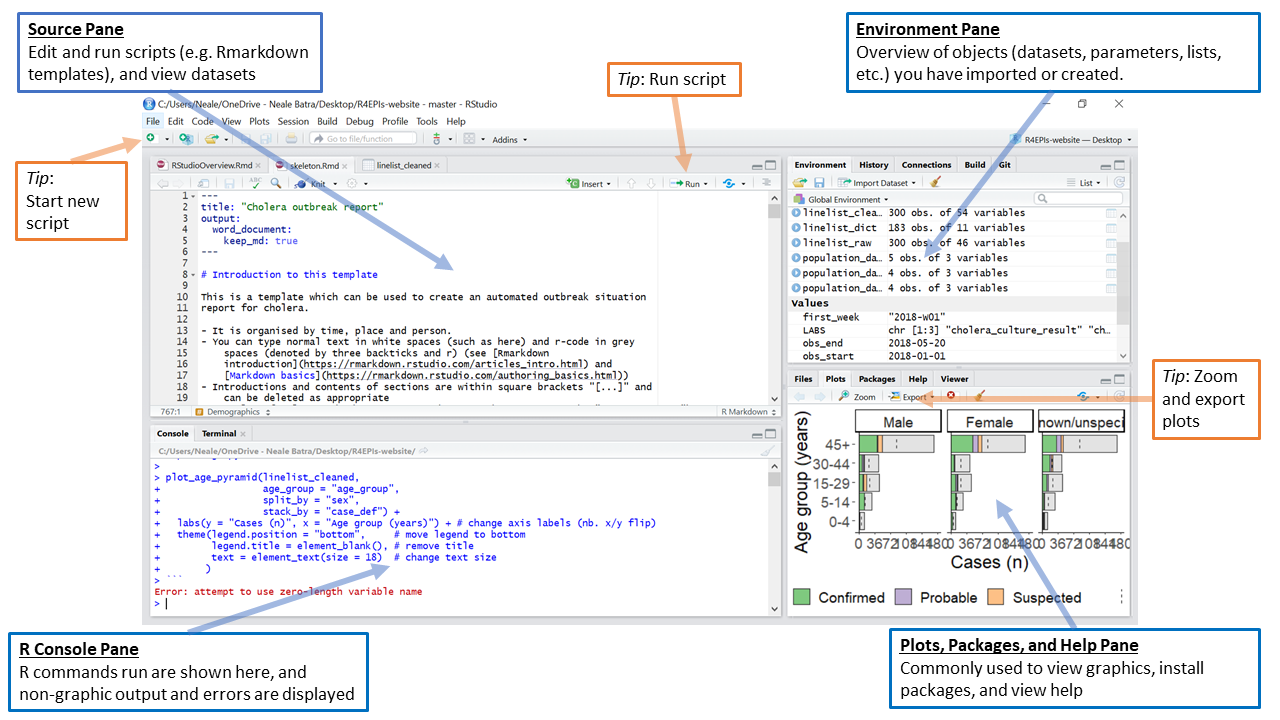
TIP: If your RStudio displays only one left pane it is because you have no scripts open yet.
The Source Pane
This pane, by default in the upper-left, is a space to edit, run, and save your scripts. Scripts contain the commands you want to run. This pane can also display datasets (data frames) for viewing.
For Stata users, this pane is similar to your Do-file and Data Editor windows.
The R Console Pane
The R Console, by default the left or lower-left pane in R Studio, is the home of the R “engine”. This is where the commands are actually run and non-graphic outputs and error/warning messages appear. You can directly enter and run commands in the R Console, but realize that these commands are not saved as they are when running commands from a script.
If you are familiar with Stata, the R Console is like the Command Window and also the Results Window.
The Environment Pane
This pane, by default in the upper-right, is most often used to see brief summaries of objects in the R Environment in the current session. These objects could include imported, modified, or created datasets, parameters you have defined (e.g. a specific epi week for the analysis), or vectors or lists you have defined during analysis (e.g. names of regions). You can click on the arrow next to a data frame name to see its variables.
In Stata, this is most similar to the Variables Manager window.
This pane also contains History where you can see commands that you can previously. It also has a “Tutorial” tab where you can complete interactive R tutorials if you have the learnr package installed. It also has a “Connections” pane for external connections, and can have a “Git” pane if you choose to interface with Github.
Plots, Viewer, Packages, and Help Pane
The lower-right pane includes several important tabs. Typical plot graphics including maps will display in the Plot pane. Interactive or HTML outputs will display in the Viewer pane. The Help pane can display documentation and help files. The Files pane is a browser which can be used to open or delete files. The Packages pane allows you to see, install, update, delete, load/unload R packages, and see which version of the package you have. To learn more about packages see the packages section below.
This pane contains the Stata equivalents of the Plots Manager and Project Manager windows.
RStudio settings
Change RStudio settings and appearance in the Tools drop-down menu, by selecting Global Options. There you can change the default settings, including appearance/background color.
Restart
If your R freezes, you can re-start R by going to the Session menu and clicking “Restart R”. This avoids the hassle of closing and opening RStudio. Everything in your R environment will be removed when you do this.
Keyboard shortcuts
Some very useful keyboard shortcuts are below. See all the keyboard shortcuts for Windows, Max, and Linux in the second page of this RStudio user interface cheatsheet.
| Windows/Linux | Mac | Action |
|---|---|---|
| Esc | Esc | Interrupt current command (useful if you accidentally ran an incomplete command and cannot escape seeing “+” in the R console) |
| Ctrl+s | Cmd+s | Save (script) |
| Tab | Tab | Auto-complete |
| Ctrl + Enter | Cmd + Enter | Run current line(s)/selection of code |
| Ctrl + Shift + C | Cmd + Shift + c | comment/uncomment the highlighted lines |
| Alt + - | Option + - | Insert <- |
| Ctrl + Shift + m | Cmd + Shift + m | Insert %>% |
| Ctrl + l | Cmd + l | Clear the R console |
| Ctrl + Alt + b | Cmd + Option + b | Run from start to current line |
| Ctrl + Alt + t | Cmd + Option + t | Run the current code section (R Markdown) |
| Ctrl + Alt + i | Cmd + Shift + r | Insert code chunk (into R Markdown) |
| Ctrl + Alt + c | Cmd + Option + c | Run current code chunk (R Markdown) |
| up/down arrows in R console | Same | Toggle through recently run commands |
| Shift + up/down arrows in script | Same | Select multiple code lines |
| Ctrl + f | Cmd + f | Find and replace in current script |
| Ctrl + Shift + f | Cmd + Shift + f | Find in files (search/replace across many scripts) |
| Alt + l | Cmd + Option + l | Fold selected code |
| Shift + Alt + l | Cmd + Shift + Option+l | Unfold selected code |
TIP: Use your Tab key when typing to engage RStudio’s auto-complete functionality. This can prevent spelling errors. Press Tab while typing to produce a drop-down menu of likely functions and objects, based on what you have typed so far.
3.6 Functions
Functions are at the core of using R. Functions are how you perform tasks and operations. Many functions come installed with R, many more are available for download in packages (explained in the packages section), and you can even write your own custom functions!
This basics section on functions explains:
- What a function is and how they work
- What function arguments are
- How to get help understanding a function
A quick note on syntax: In this handbook, functions are written in code-text with open parentheses, like this: filter(). As explained in the packages section, functions are downloaded within packages. In this handbook, package names are written in bold, like dplyr. Sometimes in example code you may see the function name linked explicitly to the name of its package with two colons (::) like this: dplyr::filter(). The purpose of this linkage is explained in the packages section.
Simple functions
A function is like a machine that receives inputs, does some action with those inputs, and produces an output. What the output is depends on the function.
Functions typically operate upon some object placed within the function’s parentheses. For example, the function sqrt() calculates the square root of a number:
sqrt(49)[1] 7The object provided to a function also can be a column in a dataset (see the Objects section for detail on all the kinds of objects). Because R can store multiple datasets, you will need to specify both the dataset and the column. One way to do this is using the $ notation to link the name of the dataset and the name of the column (dataset$column). In the example below, the function summary() is applied to the numeric column age in the dataset linelist, and the output is a summary of the column’s numeric and missing values.
# Print summary statistics of column 'age' in the dataset 'linelist'
summary(linelist$age) Min. 1st Qu. Median Mean 3rd Qu. Max. NA's
0.00 6.00 13.00 16.07 23.00 84.00 86 NOTE: Behind the scenes, a function represents complex additional code that has been wrapped up for the user into one easy command.
Functions with multiple arguments
Functions often ask for several inputs, called arguments, located within the parentheses of the function, usually separated by commas.
- Some arguments are required for the function to work correctly, others are optional
- Optional arguments have default settings
- Arguments can take character, numeric, logical (TRUE/FALSE), and other inputs
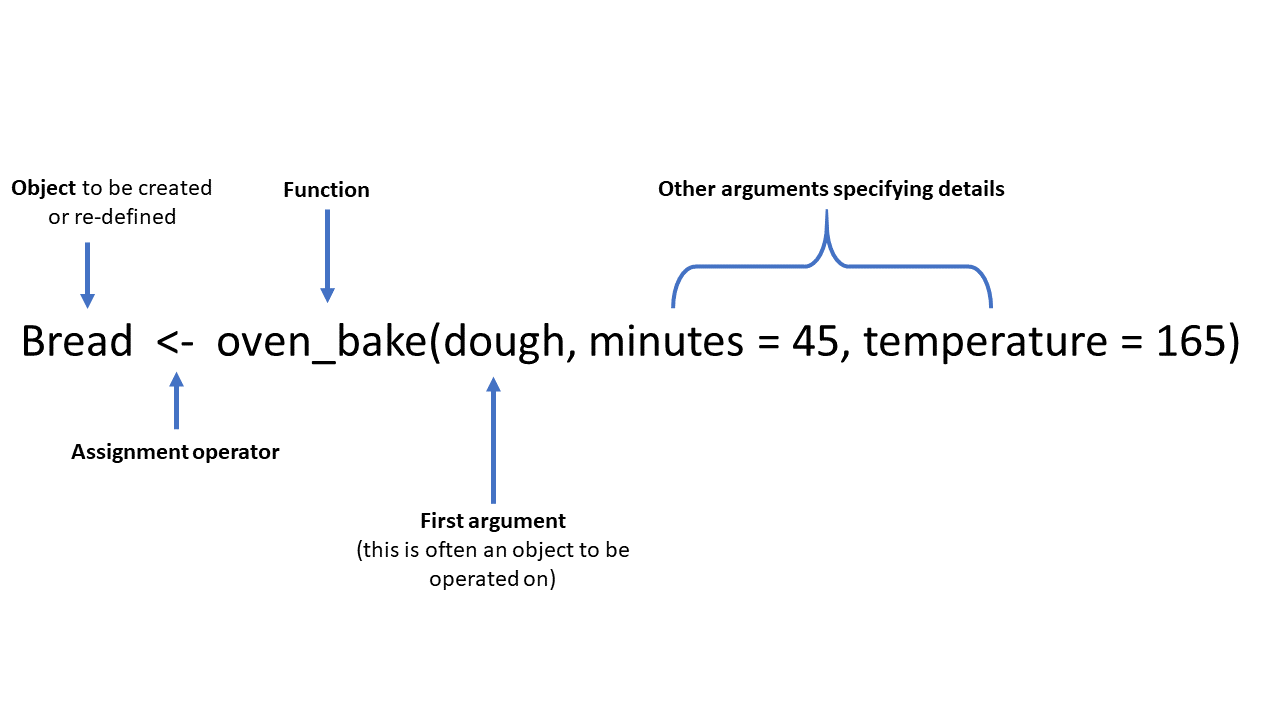
Here is a fun fictional function, called oven_bake(), as an example of a typical function. It takes an input object (e.g. a dataset, or in this example “dough”) and performs operations on it as specified by additional arguments (minutes = and temperature =). The output can be printed to the console, or saved as an object using the assignment operator <-.
In a more realistic example, the age_pyramid() command below produces an age pyramid plot based on defined age groups and a binary split column, such as gender. The function is given three arguments within the parentheses, separated by commas. The values supplied to the arguments establish linelist as the dataframe to use, age_cat5 as the column to count, and gender as the binary column to use for splitting the pyramid by color.
# Create an age pyramid
age_pyramid(data = linelist, age_group = "age_cat5", split_by = "gender")
The above command can be equivalently written as below, in a longer style with a new line for each argument. This style can be easier to read, and easier to write “comments” with # to explain each part (commenting extensively is good practice!). To run this longer command you can highlight the entire command and click “Run”, or just place your cursor in the first line and then press the Ctrl and Enter keys simultaneously.
# Create an age pyramid
age_pyramid(
data = linelist, # use case linelist
age_group = "age_cat5", # provide age group column
split_by = "gender" # use gender column for two sides of pyramid
)
The first half of an argument assignment (e.g. data =) does not need to be specified if the arguments are written in a specific order (specified in the function’s documentation). The below code produces the exact same pyramid as above, because the function expects the argument order: data frame, age_group variable, split_by variable.
# This command will produce the exact same graphic as above
age_pyramid(linelist, "age_cat5", "gender")A more complex age_pyramid() command might include the optional arguments to:
- Show proportions instead of counts (set
proportional = TRUEwhen the default isFALSE)
- Specify the two colors to use (
pal =is short for “palette” and is supplied with a vector of two color names. See the objects page for how the functionc()makes a vector)
NOTE: For arguments that you specify with both parts of the argument (e.g. proportional = TRUE), their order among all the arguments does not matter.
age_pyramid(
linelist, # use case linelist
"age_cat5", # age group column
"gender", # split by gender
proportional = TRUE, # percents instead of counts
pal = c("orange", "purple") # colors
)
Writing Functions
R is a language that is oriented around functions, so you should feel empowered to write your own functions. Creating functions brings several advantages:
- To facilitate modular programming - the separation of code in to independent and manageable pieces
- Replace repetitive copy-and-paste, which can be error prone
- Give pieces of code memorable names
How to write a function is covered in-depth in the Writing functions page.
3.7 Packages
Packages contain functions.
An R package is a shareable bundle of code and documentation that contains pre-defined functions. Users in the R community develop packages all the time catered to specific problems, it is likely that one can help with your work! You will install and use hundreds of packages in your use of R.
On installation, R contains “base” packages and functions that perform common elementary tasks. But many R users create specialized functions, which are verified by the R community and which you can download as a package for your own use. In this handbook, package names are written in bold. One of the more challenging aspects of R is that there are often many functions or packages to choose from to complete a given task.
Install and load
Functions are contained within packages which can be downloaded (“installed”) to your computer from the internet. Once a package is downloaded, it is stored in your “library”. You can then access the functions it contains during your current R session by “loading” the package.
Think of R as your personal library: When you download a package, your library gains a new book of functions, but each time you want to use a function in that book, you must borrow (“load”) that book from your library.
In summary: to use the functions available in an R package, 2 steps must be implemented:
- The package must be installed (once), and
- The package must be loaded (each R session)
Your library
Your “library” is actually a folder on your computer, containing a folder for each package that has been installed. Find out where R is installed in your computer, and look for a folder called “win-library”. For example: R\win-library\4.0 (the 4.0 is the R version - you’ll have a different library for each R version you’ve downloaded).
You can print the file path to your library by entering .libPaths() (empty parentheses). This becomes especially important if working with R on network drives.
Install from CRAN
Most often, R users download packages from CRAN. CRAN (Comprehensive R Archive Network) is an online public warehouse of R packages that have been published by R community members.
Are you worried about viruses and security when downloading a package from CRAN? Read this article on the topic.
How to install and load
In this handbook, we suggest using the pacman package (short for “package manager”). It offers a convenient function p_load() which will install a package if necessary and load it for use in the current R session.
The syntax quite simple. Just list the names of the packages within the p_load() parentheses, separated by commas. This command will install the rio, tidyverse, and here packages if they are not yet installed, and will load them for use. This makes the p_load() approach convenient and concise if sharing scripts with others. Note that package names are case-sensitive.
# Install (if necessary) and load packages for use
pacman::p_load(rio, tidyverse, here)Note that we have used the syntax pacman::p_load() which explicitly writes the package name (pacman) prior to the function name (p_load()), connected by two colons ::. This syntax is useful because it also loads the pacman package (assuming it is already installed).
There are alternative base R functions that you will see often. The base R function for installing a package is install.packages(). The name of the package to install must be provided in the parentheses in quotes. If you want to install multiple packages in one command, they must be listed within a character vector c().
Note: this command installs a package, but does not load it for use in the current session.
# install a single package with base R
install.packages("tidyverse")
# install multiple packages with base R
install.packages(c("tidyverse", "rio", "here"))Installation can also be accomplished point-and-click by going to the RStudio “Packages” pane and clicking “Install” and searching for the desired package name.
The base R function to load a package for use (after it has been installed) is library(). It can load only one package at a time (another reason to use p_load()). You can provide the package name with or without quotes.
# load packages for use, with base R
library(tidyverse)
library(rio)
library(here)To check whether a package in installed and/or loaded, you can view the Packages pane in RStudio. If the package is installed, it is shown there with version number. If its box is checked, it is loaded for the current session.
Install from Github
Sometimes, you need to install a package that is not yet available from CRAN. Or perhaps the package is available on CRAN but you want the development version with new features not yet offered in the more stable published CRAN version. These are often hosted on the website github.com in a free, public-facing code “repository”. Read more about Github in the handbook page on [Version control and collaboration with Git and Github].
To download R packages from Github, you can use the function p_load_gh() from pacman, which will install the package if necessary, and load it for use in your current R session. Alternatives to install include using the remotes or devtools packages. Read more about all the pacman functions in the package documentation.
To install from Github, you have to provide more information. You must provide:
- The Github ID of the repository owner
- The name of the repository that contains the package
- (optional) The name of the “branch” (specific development version) you want to download
In the examples below, the first word in the quotation marks is the Github ID of the repository owner, after the slash is the name of the repository (the name of the package).
# install/load the epicontacts package from its Github repository
p_load_gh("reconhub/epicontacts")If you want to install from a “branch” (version) other than the main branch, add the branch name after an “@”, after the repository name.
# install the "timeline" branch of the epicontacts package from Github
p_load_gh("reconhub/epicontacts@timeline")If there is no difference between the Github version and the version on your computer, no action will be taken. You can “force” a re-install by instead using p_load_current_gh() with the argument update = TRUE. Read more about pacman in this online vignette
Install from ZIP or TAR
You could install the package from a URL:
packageurl <- "https://cran.r-project.org/src/contrib/Archive/dsr/dsr_0.2.2.tar.gz"
install.packages(packageurl, repos=NULL, type="source")Or, download it to your computer in a zipped file:
Option 1: using install_local() from the remotes package
remotes::install_local("~/Downloads/dplyr-master.zip")Option 2: using install.packages() from base R, providing the file path to the ZIP file and setting type = "source and repos = NULL.
install.packages("~/Downloads/dplyr-master.zip", repos=NULL, type="source")Code syntax
For clarity in this handbook, functions are sometimes preceded by the name of their package using the :: symbol in the following way: package_name::function_name()
Once a package is loaded for a session, this explicit style is not necessary. One can just use function_name(). However writing the package name is useful when a function name is common and may exist in multiple packages (e.g. plot()). Writing the package name will also load the package if it is not already loaded.
# This command uses the package "rio" and its function "import()" to import a dataset
linelist <- rio::import("linelist.xlsx", which = "Sheet1")Function help
To read more about a function, you can search for it in the Help tab of the lower-right RStudio. You can also run a command like ?thefunctionname (put the name of the function after a question mark) and the Help page will appear in the Help pane. Finally, try searching online for resources.
Update packages
You can update packages by re-installing them. You can also click the green “Update” button in your RStudio Packages pane to see which packages have new versions to install. Be aware that your old code may need to be updated if there is a major revision to how a function works!
Delete packages
Use p_delete() from pacman, or remove.packages() from base R. Alternatively, go find the folder which contains your library and manually delete the folder.
Dependencies
Packages often depend on other packages to work. These are called dependencies. If a dependency fails to install, then the package depending on it may also fail to install.
See the dependencies of a package with p_depends(), and see which packages depend on it with p_depends_reverse()
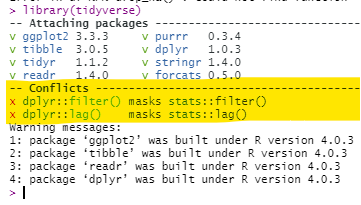
Masked functions
It is not uncommon that two or more packages contain the same function name. For example, the package dplyr has a filter() function, but so does the package stats. The default filter() function depends on the order these packages are first loaded in the R session - the later one will be the default for the command filter().
You can check the order in your Environment pane of R Studio - click the drop-down for “Global Environment” and see the order of the packages. Functions from packages lower on that drop-down list will mask functions of the same name in packages that appear higher in the drop-down list. When first loading a package, R will warn you in the console if masking is occurring, but this can be easy to miss.
Here are ways you can fix masking:
- Specify the package name in the command. For example, use
dplyr::filter()
- Re-arrange the order in which the packages are loaded (e.g. within
p_load()), and start a new R session
Detach / unload
To detach (unload) a package, use this command, with the correct package name and only one colon. Note that this may not resolve masking.
detach(package:PACKAGE_NAME_HERE, unload=TRUE)Install older version
See this guide to install an older version of a particular package.
Suggested packages
See the page on Suggested packages for a listing of packages we recommend for everyday epidemiology.
3.8 Scripts
Scripts are a fundamental part of programming. They are documents that hold your commands (e.g. functions to create and modify datasets, print visualizations, etc). You can save a script and run it again later. There are many advantages to storing and running your commands from a script (vs. typing commands one-by-one into the R console “command line”):
- Portability - you can share your work with others by sending them your scripts
- Reproducibility - so that you and others know exactly what you did
- Version control - so you can track changes made by yourself or colleagues
- Commenting/annotation - to explain to your colleagues what you have done
Commenting
In a script you can also annotate (“comment”) around your R code. Commenting is helpful to explain to yourself and other readers what you are doing. You can add a comment by typing the hash symbol (#) and writing your comment after it. The commented text will appear in a different color than the R code.
Any code written after the # will not be run. Therefore, placing a # before code is also a useful way to temporarily block a line of code (“comment out”) if you do not want to delete it). You can comment out/in multiple lines at once by highlighting them and pressing Ctrl+Shift+c (Cmd+Shift+c in Mac).
# A comment can be on a line by itself
# import data
linelist <- import("linelist_raw.xlsx") %>% # a comment can also come after code
# filter(age > 50) # It can also be used to deactivate / remove a line of code
count()- Comment on what you are doing and on why you are doing it.
- Break your code into logical sections
- Accompany your code with a text step-by-step description of what you are doing (e.g. numbered steps)
Style
It is important to be conscious of your coding style - especially if working on a team. We advocate for the tidyverse style guide. There are also packages such as styler and lintr which help you conform to this style.
A few very basic points to make your code readable to others:
* When naming objects, use only lowercase letters, numbers, and underscores _, e.g. my_data
* Use frequent spaces, including around operators, e.g. n = 1 and age_new <- age_old + 3
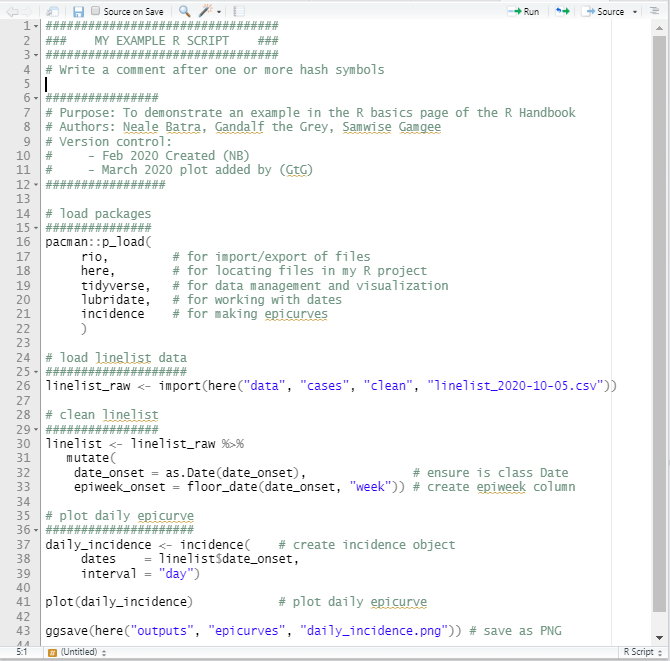
Example Script
Below is an example of a short R script. Remember, the better you succinctly explain your code in comments, the more your colleagues will like you!
R markdown
An R markdown script is a type of R script in which the script itself becomes an output document (PDF, Word, HTML, Powerpoint, etc.). These are incredibly useful and versatile tools often used to create dynamic and automated reports. Even this website and handbook is produced with R markdown scripts!
It is worth noting that beginner R users can also use R Markdown - do not be intimidated! To learn more, see the handbook page on Reports with R Markdown documents.
R notebooks
There is no difference between writing in a Rmarkdown vs an R notebook. However the execution of the document differs slightly. See this site for more details.
Shiny
Shiny apps/websites are contained within one script, which must be named app.R. This file has three components:
- A user interface (ui)
- A server function
- A call to the
shinyAppfunction
See the handbook page on Dashboards with Shiny, or this online tutorial: Shiny tutorial
In older times, the above file was split into two files (ui.R and server.R)
Code folding
You can collapse portions of code to make your script easier to read.
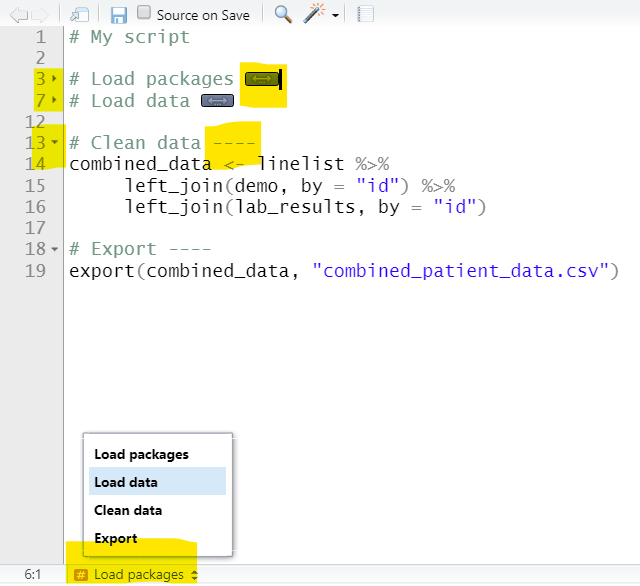
To do this, create a text header with #, write your header, and follow it with at least 4 of either dashes (-), hashes (#) or equals (=). When you have done this, a small arrow will appear in the “gutter” to the left (by the row number). You can click this arrow and the code below until the next header will collapse and a dual-arrow icon will appear in its place.
To expand the code, either click the arrow in the gutter again, or the dual-arrow icon. There are also keyboard shortcuts as explained in the RStudio section of this page.
By creating headers with #, you will also activate the Table of Contents at the bottom of your script (see below) that you can use to navigate your script. You can create sub-headers by adding more # symbols, for example # for primary, ## for seconary, and ### for tertiary headers.
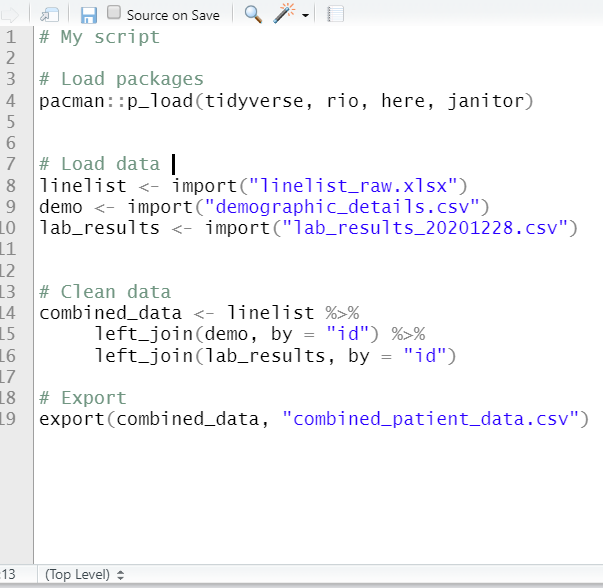
Below are two versions of an example script. On the left is the original with commented headers. On the right, four dashes have been written after each header, making them collapsible. Two of them have been collapsed, and you can see that the Table of Contents at the bottom now shows each section.
Other areas of code that are automatically eligible for folding include “braced” regions with brackets { } such as function definitions or conditional blocks (if else statements). You can read more about code folding at the RStudio site.
3.9 Working directory
The working directory is the root folder location used by R for your work - where R looks for and saves files by default. By default, it will save new files and outputs to this location, and will look for files to import (e.g. datasets) here as well.
The working directory appears in grey text at the top of the RStudio Console pane. You can also print the current working directory by running getwd() (leave the parentheses empty).

Recommended approach
See the page on R projects for details on our recommended approach to managing your working directory.
A common, efficient, and trouble-free way to manage your working directory and file paths is to combine these 3 elements in an R project-oriented workflow:
- An R Project to store all your files (see page on R projects)
- The here package to locate files (see page on Import and export)
- The rio package to import/export files (see page on Import and export)
Set by command
Until recently, many people learning R were taught to begin their scripts with a setwd() command. Please instead consider using an [R project][r_projects.qmd]-oriented workflow and read the reasons for not using setwd(). In brief, your work becomes specific to your computer, file paths used to import and export files become “brittle”, and this severely hinders collaboration and use of your code on any other computer. There are easy alternatives!
As noted above, although we do not recommend this approach in most circumstances, you can use the command setwd() with the desired folder file path in quotations, for example:
setwd("C:/Documents/R Files/My analysis")DANGER: Setting a working directory with setwd() can be “brittle” if the file path is specific to one computer. Instead, use file paths relative to an R Project root directory (with the here package).
Set manually
To set the working directory manually (the point-and-click equivalent of setwd()), click the Session drop-down menu and go to “Set Working Directory” and then “Choose Directory”. This will set the working directory for that specific R session. Note: if using this approach, you will have to do this manually each time you open RStudio.
Within an R project
If using an R project, the working directory will default to the R project root folder that contains the “.rproj” file. This will apply if you open RStudio by clicking open the R Project (the file with “.rproj” extension).
Working directory in an R markdown
In an R markdown script, the default working directory is the folder the Rmarkdown file (.Rmd) is saved within. If using an R project and here package, this does not apply and the working directory will be here() as explained in the R projects page.
If you want to change the working directory of a stand-alone R markdown (not in an R project), if you use setwd() this will only apply to that specific code chunk. To make the change for all code chunks in an R markdown, edit the setup chunk to add the root.dir = parameter, such as below:
knitr::opts_knit$set(root.dir = 'desired/directorypath')It is much easier to just use the R markdown within an R project and use the here package.
Providing file paths
Perhaps the most common source of frustration for an R beginner (at least on a Windows machine) is typing in a file path to import or export data. There is a thorough explanation of how to best input file paths in the Import and export page, but here are a few key points:
Broken paths
Below is an example of an “absolute” or “full address” file path. These will likely break if used by another computer. One exception is if you are using a shared/network drive.
C:/Users/Name/Document/Analytic Software/R/Projects/Analysis2019/data/March2019.csv Slash direction
If typing in a file path, be aware the direction of the slashes. Use forward slashes (/) to separate the components (“data/provincial.csv”). For Windows users, the default way that file paths are displayed is with back slashes (\) - so you will need to change the direction of each slash. If you use the here package as described in the R projects page the slash direction is not an issue.
Relative file paths
We generally recommend providing “relative” filepaths instead - that is, the path relative to the root of your R Project. You can do this using the here package as explained in the R projects page. A relativel filepath might look like this:
# Import csv linelist from the data/linelist/clean/ sub-folders of an R project
linelist <- import(here("data", "clean", "linelists", "marin_country.csv"))Even if using relative file paths within an R project, you can still use absolute paths to import/export data outside your R project.
3.10 Objects
Everything in R is an object, and R is an “object-oriented” language. These sections will explain:
- How to create objects (
<-) - Types of objects (e.g. data frames, vectors..)
- How to access subparts of objects (e.g. variables in a dataset)
- Classes of objects (e.g. numeric, logical, integer, double, character, factor)
Everything is an object
This section is adapted from the R4Epis project.
Everything you store in R - datasets, variables, a list of village names, a total population number, even outputs such as graphs - are objects which are assigned a name and can be referenced in later commands.
An object exists when you have assigned it a value (see the assignment section below). When it is assigned a value, the object appears in the Environment (see the upper right pane of RStudio). It can then be operated upon, manipulated, changed, and re-defined.
Defining objects (<-)
Create objects by assigning them a value with the <- operator.
You can think of the assignment operator <- as the words “is defined as”. Assignment commands generally follow a standard order:
object_name <- value (or process/calculation that produce a value)
For example, you may want to record the current epidemiological reporting week as an object for reference in later code. In this example, the object current_week is created when it is assigned the value "2018-W10" (the quote marks make this a character value). The object current_week will then appear in the RStudio Environment pane (upper-right) and can be referenced in later commands.
See the R commands and their output in the boxes below.
current_week <- "2018-W10" # this command creates the object current_week by assigning it a value
current_week # this command prints the current value of current_week object in the console[1] "2018-W10"NOTE: Note the [1] in the R console output is simply indicating that you are viewing the first item of the output
CAUTION: An object’s value can be over-written at any time by running an assignment command to re-define its value. Thus, the order of the commands run is very important.
The following command will re-define the value of current_week:
current_week <- "2018-W51" # assigns a NEW value to the object current_week
current_week # prints the current value of current_week in the console[1] "2018-W51"Equals signs =
You will also see equals signs in R code:
- A double equals sign
==between two objects or values asks a logical question: “is this equal to that?”.
- You will also see equals signs within functions used to specify values of function arguments (read about these in sections below), for example
max(age, na.rm = TRUE).
- You can use a single equals sign
=in place of<-to create and define objects, but this is discouraged. You can read about why this is discouraged here.
Datasets
Datasets are also objects (typically “dataframes”) and must be assigned names when they are imported. In the code below, the object linelist is created and assigned the value of a CSV file imported with the rio package and its import() function.
# linelist is created and assigned the value of the imported CSV file
linelist <- import("my_linelist.csv")You can read more about importing and exporting datasets with the section on Import and export.
CAUTION: A quick note on naming of objects:
- Object names must not contain spaces, but you should use underscore (_) or a period (.) instead of a space.
- Object names are case-sensitive (meaning that Dataset_A is different from dataset_A).
- Object names must begin with a letter (cannot begin with a number like 1, 2 or 3).
Outputs
Outputs like tables and plots provide an example of how outputs can be saved as objects, or just be printed without being saved. A cross-tabulation of gender and outcome using the base R function table() can be printed directly to the R console (without being saved).
# printed to R console only
table(linelist$gender, linelist$outcome)
Death Recover
f 1227 953
m 1228 950But the same table can be saved as a named object. Then, optionally, it can be printed.
# save
gen_out_table <- table(linelist$gender, linelist$outcome)
# print
gen_out_table
Death Recover
f 1227 953
m 1228 950Columns
Columns in a dataset are also objects and can be defined, over-written, and created as described below in the section on Columns.
You can use the assignment operator from base R to create a new column. Below, the new column bmi (Body Mass Index) is created, and for each row the new value is result of a mathematical operation on the row’s value in the wt_kg and ht_cm columns.
# create new "bmi" column using base R syntax
linelist$bmi <- linelist$wt_kg / (linelist$ht_cm/100)^2However, in this handbook, we emphasize a different approach to defining columns, which uses the function mutate() from the dplyr package and piping with the pipe operator (%>%). The syntax is easier to read and there are other advantages explained in the page on Cleaning data and core functions. You can read more about piping in the Piping section below.
# create new "bmi" column using dplyr syntax
linelist <- linelist %>%
mutate(bmi = wt_kg / (ht_cm/100)^2)Object structure
Objects can be a single piece of data (e.g. my_number <- 24), or they can consist of structured data.
The graphic below is borrowed from this online R tutorial. It shows some common data structures and their names. Not included in this image is spatial data, which is discussed in the GIS basics page.
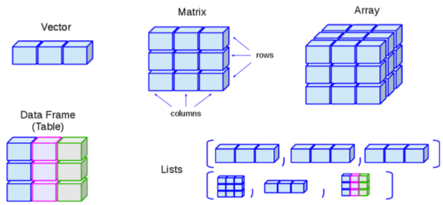
In epidemiology (and particularly field epidemiology), you will most commonly encounter data frames and vectors:
| Common structure | Explanation | Example |
|---|---|---|
| Vectors | A container for a sequence of singular objects, all of the same class (e.g. numeric, character). | “Variables” (columns) in data frames are vectors (e.g. the column age_years). |
| Data Frames | Vectors (e.g. columns) that are bound together that all have the same number of rows. | linelist is a data frame. |
Note that to create a vector that “stands alone” (is not part of a data frame) the function c() is used to combine the different elements. For example, if creating a vector of colors plot’s color scale: vector_of_colors <- c("blue", "red2", "orange", "grey")
Object classes
All the objects stored in R have a class which tells R how to handle the object. There are many possible classes, but common ones include:
4 ClassCharacter |
5 ExplanationThese are text/words/sentences “within quotation marks”. Math cannot be done on these objects. |
6 Examples“Character objects are in quotation marks” |
|
| Integer | Numbers that are whole only (no decimals) | -5, 14, or 2000 | |
| Numeric | These are numbers and can include decimals. If within quotation marks they will be considered character class. | 23.1 or 14 | |
| Factor | These are vectors that have a specified order or hierarchy of values | An variable of economic status with ordered values | |
| Date | Once R is told that certain data are Dates, these data can be manipulated and displayed in special ways. See the page on Working with dates for more information. | 2018-04-12 or 15/3/1954 or Wed 4 Jan 1980 | ||
| Logical | Values must be one of the two special values TRUE or FALSE (note these are not “TRUE” and “FALSE” in quotation marks) | TRUE or FALSE | |
| data.frame | A data frame is how R stores a typical dataset. It consists of vectors (columns) of data bound together, that all have the same number of observations (rows). | The example AJS dataset named linelist_raw contains 68 variables with 300 observations (rows) each. |
|
| tibble | tibbles are a variation on data frame, the main operational difference being that they print more nicely to the console (display first 10 rows and only columns that fit on the screen) | Any data frame, list, or matrix can be converted to a tibble with as_tibble() |
|
| list | A list is like vector, but holds other objects that can be other different classes | A list could hold a single number, and a dataframe, and a vector, and even another list within it! |
You can test the class of an object by providing its name to the function class(). Note: you can reference a specific column within a dataset using the $ notation to separate the name of the dataset and the name of the column.
class(linelist) # class should be a data frame or tibble[1] "data.frame"class(linelist$age) # class should be numeric[1] "numeric"class(linelist$gender) # class should be character[1] "character"Sometimes, a column will be converted to a different class automatically by R. Watch out for this! For example, if you have a vector or column of numbers, but a character value is inserted… the entire column will change to class character.
num_vector <- c(1,2,3,4,5) # define vector as all numbers
class(num_vector) # vector is numeric class[1] "numeric"num_vector[3] <- "three" # convert the third element to a character
class(num_vector) # vector is now character class[1] "character"One common example of this is when manipulating a data frame in order to print a table - if you make a total row and try to paste/glue together percents in the same cell as numbers (e.g. 23 (40%)), the entire numeric column above will convert to character and can no longer be used for mathematical calculations.Sometimes, you will need to convert objects or columns to another class.
7 Function
|
8 ActionConverts to character class |
|
as.numeric() |
Converts to numeric class | |
as.integer() |
Converts to integer class | |
as.Date() |
Converts to Date class - Note: see section on dates for details | |
factor() |
Converts to factor - Note: re-defining order of value levels requires extra arguments |
Likewise, there are base R functions to check whether an object IS of a specific class, such as is.numeric(), is.character(), is.double(), is.factor(), is.integer()
Here is more online material on classes and data structures in R.
Columns/Variables ($)
A column in a data frame is technically a “vector” (see table above) - a series of values that must all be the same class (either character, numeric, logical, etc).
A vector can exist independent of a data frame, for example a vector of column names that you want to include as explanatory variables in a model. To create a “stand alone” vector, use the c() function as below:
# define the stand-alone vector of character values
explanatory_vars <- c("gender", "fever", "chills", "cough", "aches", "vomit")
# print the values in this named vector
explanatory_vars[1] "gender" "fever" "chills" "cough" "aches" "vomit" Columns in a data frame are also vectors and can be called, referenced, extracted, or created using the $ symbol. The $ symbol connects the name of the column to the name of its data frame. In this handbook, we try to use the word “column” instead of “variable”.
# Retrieve the length of the vector age_years
length(linelist$age) # (age is a column in the linelist data frame)By typing the name of the dataframe followed by $ you will also see a drop-down menu of all columns in the data frame. You can scroll through them using your arrow key, select one with your Enter key, and avoid spelling mistakes!

ADVANCED TIP: Some more complex objects (e.g. a list, or an epicontacts object) may have multiple levels which can be accessed through multiple dollar signs. For example epicontacts$linelist$date_onset
Access/index with brackets ([ ])
You may need to view parts of objects, also called “indexing”, which is often done using the square brackets [ ]. Using $ on a dataframe to access a column is also a type of indexing.
my_vector <- c("a", "b", "c", "d", "e", "f") # define the vector
my_vector[5] # print the 5th element[1] "e"Square brackets also work to return specific parts of an returned output, such as the output of a summary() function:
# All of the summary
summary(linelist$age) Min. 1st Qu. Median Mean 3rd Qu. Max. NA's
0.00 6.00 13.00 16.07 23.00 84.00 86 # Just the second element of the summary, with name (using only single brackets)
summary(linelist$age)[2]1st Qu.
6 # Just the second element, without name (using double brackets)
summary(linelist$age)[[2]][1] 6# Extract an element by name, without showing the name
summary(linelist$age)[["Median"]][1] 13Brackets also work on data frames to view specific rows and columns. You can do this using the syntax dataframe[rows, columns]:
# View a specific row (2) from dataset, with all columns (don't forget the comma!)
linelist[2,]
# View all rows, but just one column
linelist[, "date_onset"]
# View values from row 2 and columns 5 through 10
linelist[2, 5:10]
# View values from row 2 and columns 5 through 10 and 18
linelist[2, c(5:10, 18)]
# View rows 2 through 20, and specific columns
linelist[2:20, c("date_onset", "outcome", "age")]
# View rows and columns based on criteria
# *** Note the dataframe must still be named in the criteria!
linelist[linelist$age > 25 , c("date_onset", "outcome", "age")]
# Use View() to see the outputs in the RStudio Viewer pane (easier to read)
# *** Note the capital "V" in View() function
View(linelist[2:20, "date_onset"])
# Save as a new object
new_table <- linelist[2:20, c("date_onset")] Note that you can also achieve the above row/column indexing on data frames and tibbles using dplyr syntax (functions filter() for rows, and select() for columns). Read more about these core functions in the Cleaning data and core functions page.
To filter based on “row number”, you can use the dplyr function row_number() with open parentheses as part of a logical filtering statement. Often you will use the %in% operator and a range of numbers as part of that logical statement, as shown below. To see the first N rows, you can also use the special dplyr function head().
# View first 100 rows
linelist %>% head(100)
# Show row 5 only
linelist %>% filter(row_number() == 5)
# View rows 2 through 20, and three specific columns (note no quotes necessary on column names)
linelist %>% filter(row_number() %in% 2:20) %>% select(date_onset, outcome, age)When indexing an object of class list, single brackets always return with class list, even if only a single object is returned. Double brackets, however, can be used to access a single element and return a different class than list.
Brackets can also be written after one another, as demonstrated below.
This visual explanation of lists indexing, with pepper shakers is humorous and helpful.
# define demo list
my_list <- list(
# First element in the list is a character vector
hospitals = c("Central", "Empire", "Santa Anna"),
# second element in the list is a data frame of addresses
addresses = data.frame(
street = c("145 Medical Way", "1048 Brown Ave", "999 El Camino"),
city = c("Andover", "Hamilton", "El Paso")
)
)Here is how the list looks when printed to the console. See how there are two named elements:
hospitals, a character vector
addresses, a data frame of addresses
my_list$hospitals
[1] "Central" "Empire" "Santa Anna"
$addresses
street city
1 145 Medical Way Andover
2 1048 Brown Ave Hamilton
3 999 El Camino El PasoNow we extract, using various methods:
my_list[1] # this returns the element in class "list" - the element name is still displayed$hospitals
[1] "Central" "Empire" "Santa Anna"my_list[[1]] # this returns only the (unnamed) character vector[1] "Central" "Empire" "Santa Anna"my_list[["hospitals"]] # you can also index by name of the list element[1] "Central" "Empire" "Santa Anna"my_list[[1]][3] # this returns the third element of the "hospitals" character vector[1] "Santa Anna"my_list[[2]][1] # This returns the first column ("street") of the address data frame street
1 145 Medical Way
2 1048 Brown Ave
3 999 El CaminoRemove objects
You can remove individual objects from your R environment by putting the name in the rm() function (no quote marks):
rm(object_name)You can remove all objects (clear your workspace) by running:
rm(list = ls(all = TRUE))8.1 Piping (%>%)
Two general approaches to working with objects are:
- Pipes/tidyverse - pipes send an object from function to function - emphasis is on the action, not the object
- Define intermediate objects - an object is re-defined again and again - emphasis is on the object
Pipes
Simply explained, the pipe operator (%>%) passes an intermediate output from one function to the next.
You can think of it as saying “then”. Many functions can be linked together with %>%.
- Piping emphasizes a sequence of actions, not the object the actions are being performed on
- Pipes are best when a sequence of actions must be performed on one object
- Pipes come from the package magrittr, which is automatically included in packages dplyr and tidyverse
- Pipes can make code more clean and easier to read, more intuitive
Read more on this approach in the tidyverse style guide
Here is a fake example for comparison, using fictional functions to “bake a cake”. First, the pipe method:
# A fake example of how to bake a cake using piping syntax
cake <- flour %>% # to define cake, start with flour, and then...
add(eggs) %>% # add eggs
add(oil) %>% # add oil
add(water) %>% # add water
mix_together( # mix together
utensil = spoon,
minutes = 2) %>%
bake(degrees = 350, # bake
system = "fahrenheit",
minutes = 35) %>%
let_cool() # let it cool downHere is another link describing the utility of pipes.
Piping is not a base function. To use piping, the magrittr package must be installed and loaded (this is typically done by loading tidyverse or dplyr package which include it). You can read more about piping in the magrittr documentation.
Note that just like other R commands, pipes can be used to just display the result, or to save/re-save an object, depending on whether the assignment operator <- is involved. See both below:
# Create or overwrite object, defining as aggregate counts by age category (not printed)
linelist_summary <- linelist %>%
count(age_cat)# Print the table of counts in the console, but don't save it
linelist %>%
count(age_cat) age_cat n
1 0-4 1095
2 5-9 1095
3 10-14 941
4 15-19 743
5 20-29 1073
6 30-49 754
7 50-69 95
8 70+ 6
9 <NA> 86%<>%
This is an “assignment pipe” from the magrittr package, which pipes an object forward and also re-defines the object. It must be the first pipe operator in the chain. It is shorthand. The below two commands are equivalent:
linelist <- linelist %>%
filter(age > 50)
linelist %<>% filter(age > 50)Define intermediate objects
This approach to changing objects/dataframes may be better if:
- You need to manipulate multiple objects
- There are intermediate steps that are meaningful and deserve separate object names
Risks:
- Creating new objects for each step means creating lots of objects. If you use the wrong one you might not realize it!
- Naming all the objects can be confusing
- Errors may not be easily detectable
Either name each intermediate object, or overwrite the original, or combine all the functions together. All come with their own risks.
Below is the same fake “cake” example as above, but using this style:
# a fake example of how to bake a cake using this method (defining intermediate objects)
batter_1 <- left_join(flour, eggs)
batter_2 <- left_join(batter_1, oil)
batter_3 <- left_join(batter_2, water)
batter_4 <- mix_together(object = batter_3, utensil = spoon, minutes = 2)
cake <- bake(batter_4, degrees = 350, system = "fahrenheit", minutes = 35)
cake <- let_cool(cake)Combine all functions together - this is difficult to read:
# an example of combining/nesting mutliple functions together - difficult to read
cake <- let_cool(bake(mix_together(batter_3, utensil = spoon, minutes = 2), degrees = 350, system = "fahrenheit", minutes = 35))8.2 Key operators and functions
This section details operators in R, such as:
- Definitional operators
- Relational operators (less than, equal too..)
- Logical operators (and, or…)
- Handling missing values
- Mathematical operators and functions (+/-, >, sum(), median(), …)
- The
%in%operator
Assignment operators
<-
The basic assignment operator in R is <-. Such that object_name <- value.
This assignment operator can also be written as =. We advise use of <- for general R use.
We also advise surrounding such operators with spaces, for readability.
<<-
If Writing functions, or using R in an interactive way with sourced scripts, then you may need to use this assignment operator <<- (from base R). This operator is used to define an object in a higher ‘parent’ R Environment. See this online reference.
%<>%
This is an “assignment pipe” from the magrittr package, which pipes an object forward and also re-defines the object. It must be the first pipe operator in the chain. It is shorthand, as shown below in two equivalent examples:
linelist <- linelist %>%
mutate(age_months = age_years * 12)The above is equivalent to the below:
linelist %<>% mutate(age_months = age_years * 12)%<+%
This is used to add data to phylogenetic trees with the ggtree package. See the page on Phylogenetic trees or this online resource book.
Relational and logical operators
Relational operators compare values and are often used when defining new variables and subsets of datasets. Here are the common relational operators in R:
9 MeaningEqual to |
10 Operator
|
11 Example
|
12 Example Result
|
|
| Not equal to | != |
2 != 0 |
TRUE |
|
| Greater than | > |
4 > 2 |
TRUE |
|
| Less than | < |
4 < 2 |
FALSE |
|
| Greater than or equal to | >= |
6 >= 4 |
TRUE |
|
| Less than or equal to | <= |
6 <= 4 |
FALSE |
|
| Value is missing | is.na() |
is.na(7) |
FALSE (see page on Missing data) |
|
| Value is not missing | !is.na() |
!is.na(7) |
TRUE |
Logical operators, such as AND and OR, are often used to connect relational operators and create more complicated criteria. Complex statements might require parentheses ( ) for grouping and order of application.
| Meaning | Operator |
|---|---|
| AND | & |
| OR | | (vertical bar) |
| Parentheses | ( ) Used to group criteria together and clarify order of operations |
For example, below, we have a linelist with two variables we want to use to create our case definition, hep_e_rdt, a test result and other_cases_in_hh, which will tell us if there are other cases in the household. The command below uses the function case_when() to create the new variable case_def such that:
linelist_cleaned <- linelist %>%
mutate(case_def = case_when(
is.na(rdt_result) & is.na(other_case_in_home) ~ NA_character_,
rdt_result == "Positive" ~ "Confirmed",
rdt_result != "Positive" & other_cases_in_home == "Yes" ~ "Probable",
TRUE ~ "Suspected"
))| Criteria in example above | Resulting value in new variable “case_def” |
|---|---|
If the value for variables rdt_result and other_cases_in_home are missing |
NA (missing) |
If the value in rdt_result is “Positive” |
“Confirmed” |
If the value in rdt_result is NOT “Positive” AND the value in other_cases_in_home is “Yes” |
“Probable” |
| If one of the above criteria are not met | “Suspected” |
Note that R is case-sensitive, so “Positive” is different than “positive”…
Missing values
In R, missing values are represented by the special value NA (a “reserved” value) (capital letters N and A - not in quotation marks). If you import data that records missing data in another way (e.g. 99, “Missing”, or .), you may want to re-code those values to NA. How to do this is addressed in the Import and export page.
To test whether a value is NA, use the special function is.na(), which returns TRUE or FALSE.
rdt_result <- c("Positive", "Suspected", "Positive", NA) # two positive cases, one suspected, and one unknown
is.na(rdt_result) # Tests whether the value of rdt_result is NA[1] FALSE FALSE FALSE TRUERead more about missing, infinite, NULL, and impossible values in the page on Missing data. Learn how to convert missing values when importing data in the page on Import and export.
Mathematics and statistics
All the operators and functions in this page are automatically available using base R.
Mathematical operators
These are often used to perform addition, division, to create new columns, etc. Below are common mathematical operators in R. Whether you put spaces around the operators is not important.
| Purpose | Example in R |
|---|---|
| addition | 2 + 3 |
| subtraction | 2 - 3 |
| multiplication | 2 * 3 |
| division | 30 / 5 |
| exponent | 2^3 |
| order of operations | ( ) |
Mathematical functions
| Purpose | Function |
|---|---|
| rounding | round(x, digits = n) |
| rounding | janitor::round_half_up(x, digits = n) |
| ceiling (round up) | ceiling(x) |
| floor (round down) | floor(x) |
| absolute value | abs(x) |
| square root | sqrt(x) |
| exponent | exponent(x) |
| natural logarithm | log(x) |
| log base 10 | log10(x) |
| log base 2 | log2(x) |
Note: for round() the digits = specifies the number of decimal placed. Use signif() to round to a number of significant figures.
Scientific notation
The likelihood of scientific notation being used depends on the value of the scipen option.
From the documentation of ?options: scipen is a penalty to be applied when deciding to print numeric values in fixed or exponential notation. Positive values bias towards fixed and negative towards scientific notation: fixed notation will be preferred unless it is more than ‘scipen’ digits wider.
If it is set to a low number (e.g. 0) it will be “turned on” always. To “turn off” scientific notation in your R session, set it to a very high number, for example:
# turn off scientific notation
options(scipen=999)Rounding
DANGER: round() uses “banker’s rounding” which rounds up from a .5 only if the upper number is even. Use round_half_up() from janitor to consistently round halves up to the nearest whole number. See this explanation
# use the appropriate rounding function for your work
round(c(2.5, 3.5))[1] 2 4janitor::round_half_up(c(2.5, 3.5))[1] 3 4Statistical functions
CAUTION: The functions below will by default include missing values in calculations. Missing values will result in an output of NA, unless the argument na.rm = TRUE is specified. This can be written shorthand as na.rm = T.
| Objective | Function |
|---|---|
| mean (average) | mean(x, na.rm=T) |
| median | median(x, na.rm=T) |
| standard deviation | sd(x, na.rm=T) |
| quantiles* | quantile(x, probs) |
| sum | sum(x, na.rm=T) |
| minimum value | min(x, na.rm=T) |
| maximum value | max(x, na.rm=T) |
| range of numeric values | range(x, na.rm=T) |
| summary** | summary(x) |
Notes:
*quantile():xis the numeric vector to examine, andprobs =is a numeric vector with probabilities within 0 and 1.0, e.gc(0.5, 0.8, 0.85)**summary(): gives a summary on a numeric vector including mean, median, and common percentiles
DANGER: If providing a vector of numbers to one of the above functions, be sure to wrap the numbers within c() .
# If supplying raw numbers to a function, wrap them in c()
mean(1, 6, 12, 10, 5, 0) # !!! INCORRECT !!! [1] 1mean(c(1, 6, 12, 10, 5, 0)) # CORRECT[1] 5.666667Other useful functions
| Objective | Function | Example |
|---|---|---|
| create a sequence | seq(from, to, by) | seq(1, 10, 2) |
| repeat x, n times | rep(x, ntimes) | rep(1:3, 2) or rep(c("a", "b", "c"), 3) |
| subdivide a numeric vector | cut(x, n) | cut(linelist$age, 5) |
| take a random sample | sample(x, size) | sample(linelist$id, size = 5, replace = TRUE) |
%in%
A very useful operator for matching values, and for quickly assessing if a value is within a vector or dataframe.
my_vector <- c("a", "b", "c", "d")"a" %in% my_vector[1] TRUE"h" %in% my_vector[1] FALSETo ask if a value is not %in% a vector, put an exclamation mark (!) in front of the logic statement:
# to negate, put an exclamation in front
!"a" %in% my_vector[1] FALSE!"h" %in% my_vector[1] TRUE%in% is very useful when using the dplyr function case_when(). You can define a vector previously, and then reference it later. For example:
affirmative <- c("1", "Yes", "YES", "yes", "y", "Y", "oui", "Oui", "Si")
linelist <- linelist %>%
mutate(child_hospitaled = case_when(
hospitalized %in% affirmative & age < 18 ~ "Hospitalized Child",
TRUE ~ "Not"))Note: If you want to detect a partial string, perhaps using str_detect() from stringr, it will not accept a character vector like c("1", "Yes", "yes", "y"). Instead, it must be given a regular expression - one condensed string with OR bars, such as “1|Yes|yes|y”. For example, str_detect(hospitalized, "1|Yes|yes|y"). See the page on Characters and strings for more information.
You can convert a character vector to a named regular expression with this command:
affirmative <- c("1", "Yes", "YES", "yes", "y", "Y", "oui", "Oui", "Si")
affirmative[1] "1" "Yes" "YES" "yes" "y" "Y" "oui" "Oui" "Si" # condense to
affirmative_str_search <- paste0(affirmative, collapse = "|") # option with base R
affirmative_str_search <- str_c(affirmative, collapse = "|") # option with stringr package
affirmative_str_search[1] "1|Yes|YES|yes|y|Y|oui|Oui|Si"12.1 Errors & warnings
This section explains:
- The difference between errors and warnings
- General syntax tips for writing R code
- Code assists
Common errors and warnings and troubleshooting tips can be found in the page on Errors and help.
Error versus Warning
When a command is run, the R Console may show you warning or error messages in red text.
A warning means that R has completed your command, but had to take additional steps or produced unusual output that you should be aware of.
An error means that R was not able to complete your command.
Look for clues:
The error/warning message will often include a line number for the problem.
If an object “is unknown” or “not found”, perhaps you spelled it incorrectly, forgot to call a package with library(), or forgot to re-run your script after making changes.
If all else fails, copy the error message into Google along with some key terms - chances are that someone else has worked through this already!
General syntax tips
A few things to remember when writing commands in R, to avoid errors and warnings:
- Always close parentheses - tip: count the number of opening “(” and closing parentheses “)” for each code chunk
- Avoid spaces in column and object names. Use underscore ( _ ) or periods ( . ) instead
- Keep track of and remember to separate a function’s arguments with commas
- R is case-sensitive, meaning
Variable_Ais different fromvariable_A
Code assists
Any script (RMarkdown or otherwise) will give clues when you have made a mistake. For example, if you forgot to write a comma where it is needed, or to close a parentheses, RStudio will raise a flag on that line, on the right side of the script, to warn you.